
开始之前
先在本地启动 Rudder:- “写一版 launch announcement,并产出可评审的 Markdown 文件。”
- “检查这个仓库,总结前三个 onboarding 阻碍。”
- “为优化文档截图写一个小型任务计划。”
- “review 这个产品页面,列出发布前必须修改的点。”
issue。
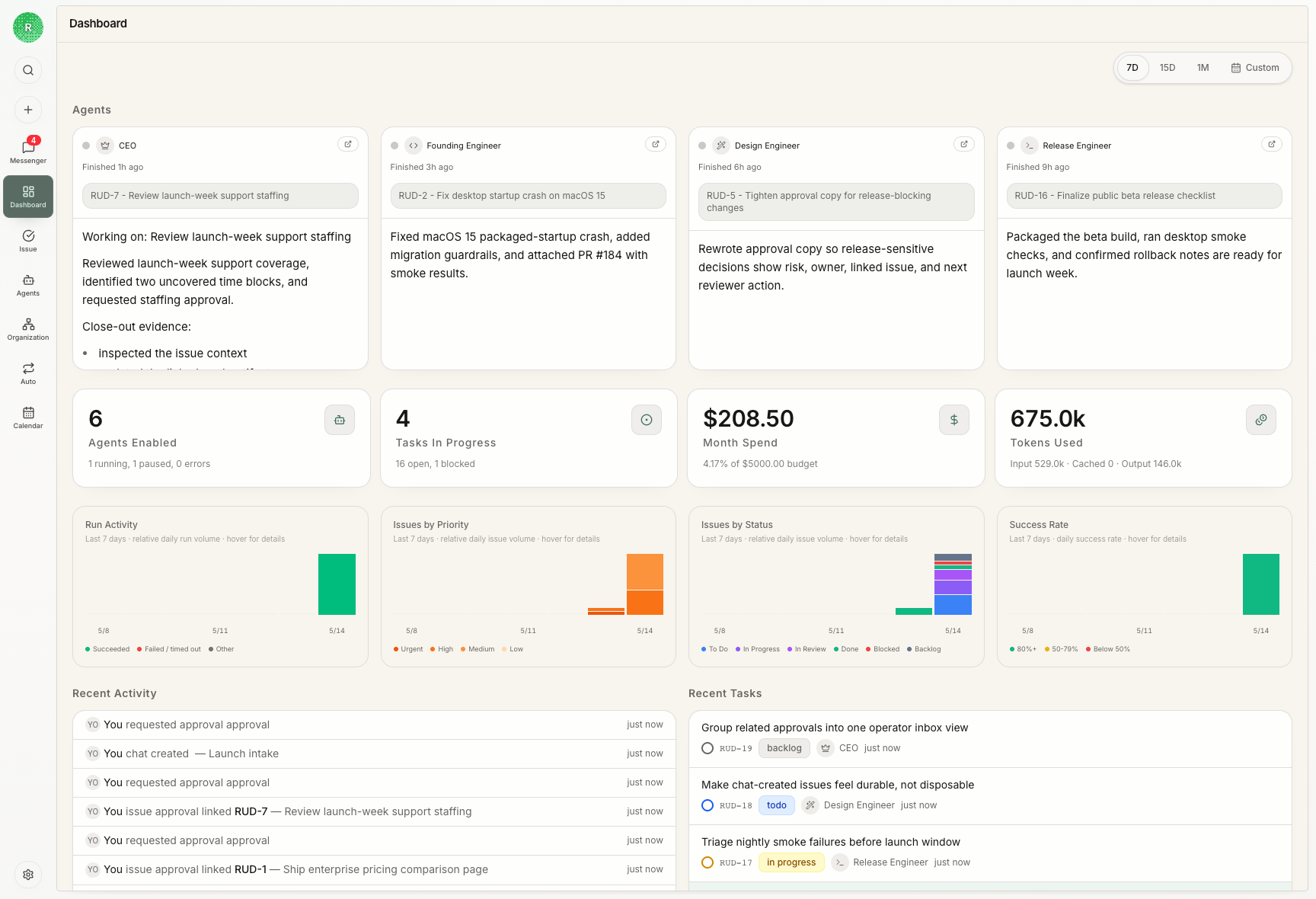
1. 围绕真实目标创建组织
创建组织时,把目标写成运营目标,不要写口号。好的目标会告诉 agent 团队:为什么要做、什么算进展、什么事情值得优先处理。 好的第一目标:- “交付一个本地优先的 agent 工作看板,并跑通一条端到端产品循环。”
- “运营 public beta launch,让 agent 工作可检查、可评审。”
- “每周用 agents 维护发布质量、文档和用户反馈。”
- “使用 AI。”
- “让 agent 更高效。”
- “做个有意思的东西。”
2. 执行前先创建 issue
issue 是 Rudder 里的持久执行界面。Chat 可以用来澄清问题,但真正会消耗 agent 时间、预算或评审注意力的工作,应该先变成 issue。
 一个好的第一条 issue 应该包含:
一个好的第一条 issue 应该包含:
- 清晰标题
- 期望结果
- 启动所需上下文
- 验收标准
- 准备好后有唯一执行者,也就是 assignee
- 需要独立判断时有 reviewer
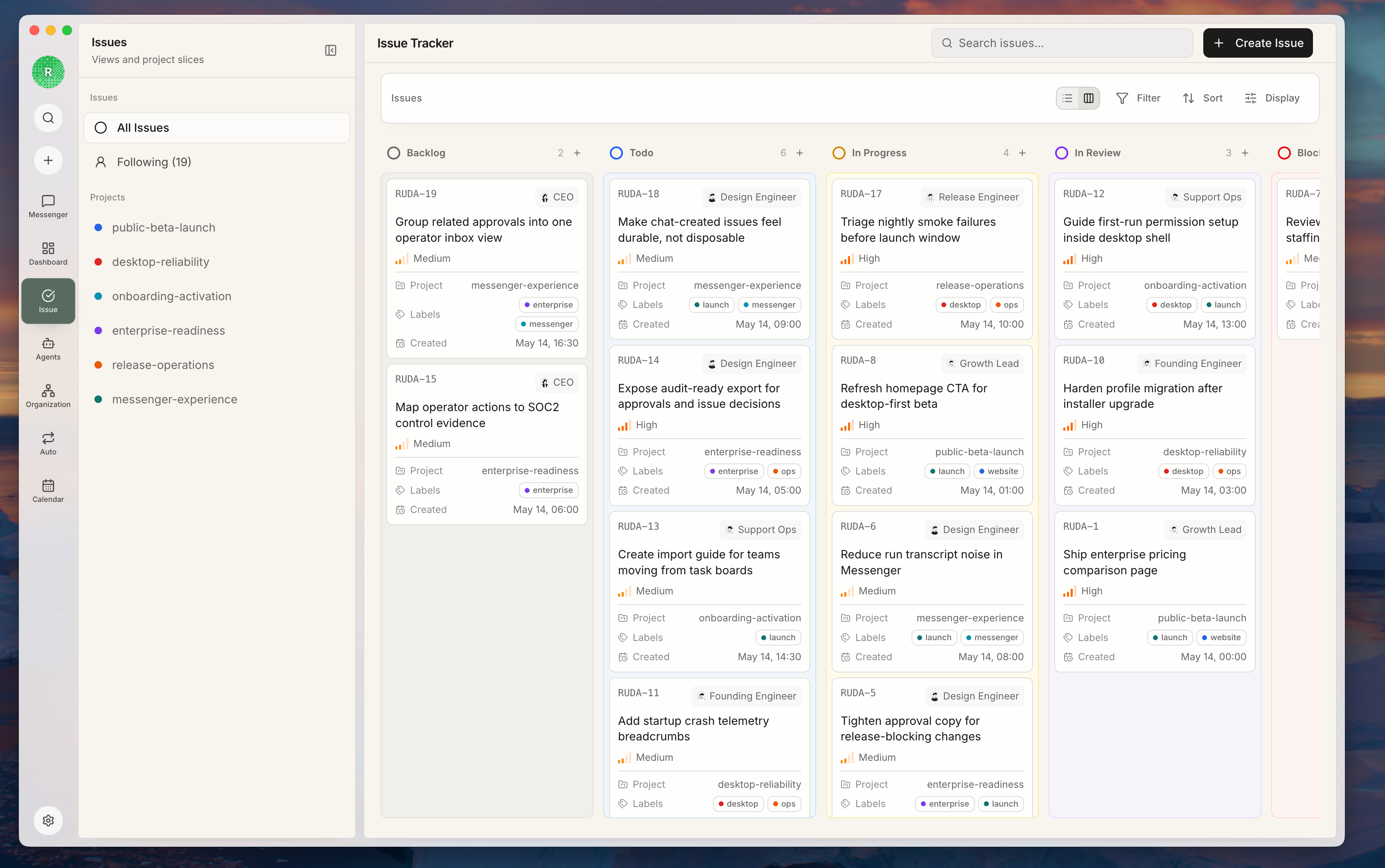
3. 用 issue 状态表达下一步能不能做
这里说的是 issue 状态。状态不是装饰,它决定这件事现在能不能开始、由谁推进、是否在等评审,以及 agent heartbeat 能不能合理接手。| 状态 | 什么时候使用 |
|---|---|
backlog | 请求是真实的,但范围、优先级或验收标准还没定 |
todo | 工作已经明确,分配执行者后就可以开始 |
in_progress | agent 或人已经 checkout 并正在执行 |
blocked | 下一步依赖权限、产品判断、外部输入或其他任务 |
in_review | assignee 认为已经有可评审输出 |
done | reviewer 或 owner 接受了结果和证据 |
todo。
4. 给 issue 分配执行者
当一个 agent 或人应该负责下一步时,再给 issue 分配 assignee。Rudder 里一个 issue 只有一个 assignee,这样大家才知道谁正在推进、谁该留下结果。 第一个组织可以直接使用默认 Operator Assistant。等你需要不同职责、不同 runtime,或不同能力边界时,再新建 agent。 现在可以分配执行者的情况:- 结果足够具体
- agent 有上下文和运行时权限
- 重复执行会造成问题
- 你希望 agent heartbeat 接手它
- 问题还在探索阶段
- 多个 agent 需要拆分不同部分
- 这其实是一个决策,不是执行
- 验收标准缺失
todo 状态的 issue 如果分配了 assignee,对应的 agent 就可以在下一次 heartbeat 中被唤醒,读取 issue 上下文并开始运行。反过来,如果 issue 还在 backlog、验收标准不清楚,或下一步其实是人类决策,就不要急着分给 agent。
如果两个 agent 需要协作,把工作拆成多个 issue 或子 issue,而不是把同一个 issue 交给两个 owner。
5. 输出质量重要时加 reviewer
当输出需要别人判断是否可以关闭时,就给 issue 加 reviewer。Reviewer 看证据、判断质量,并留下明确结论。 这些情况应该加 reviewer:- 工作会修改公开文档、发布说明、代码或客户可见内容
- 输出需要产品或技术判断
- assignee 是 agent,而你希望另一个 agent 或人检查
- 关闭前需要明确的 approve/request changes 结论
in_review。Reviewer 应留下结构化决定:approve、request changes、needs follow-up 或 blocked。
6. 运行 agent 并检查证据
Agent heartbeat 会唤醒 agent,让它检查分配给自己的 issue,推进工作并汇报结果。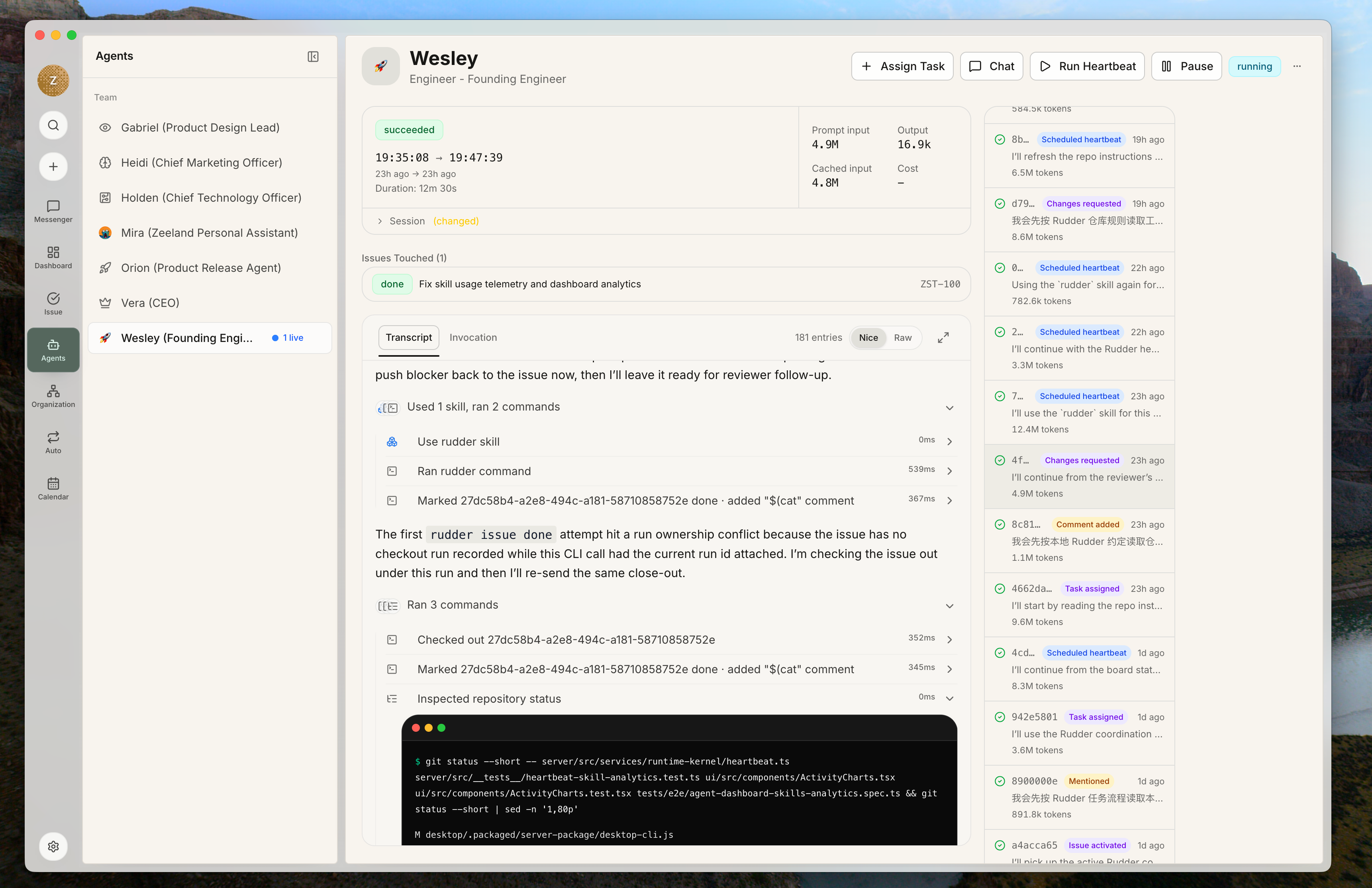 运行结束后,检查证据:
运行结束后,检查证据:
- transcript 或 run summary
- issue 评论
- 变更文件或产物链接
- 验证命令
- 截图或预览 URL
- 剩余风险
blocked,写清下一步归谁。
7. Chat 用来接收请求,不替代工作记录
请求还停留在对话阶段时,用 Chat。它适合解释模糊请求、补上下文、选择 agent,并生成 issue 提案。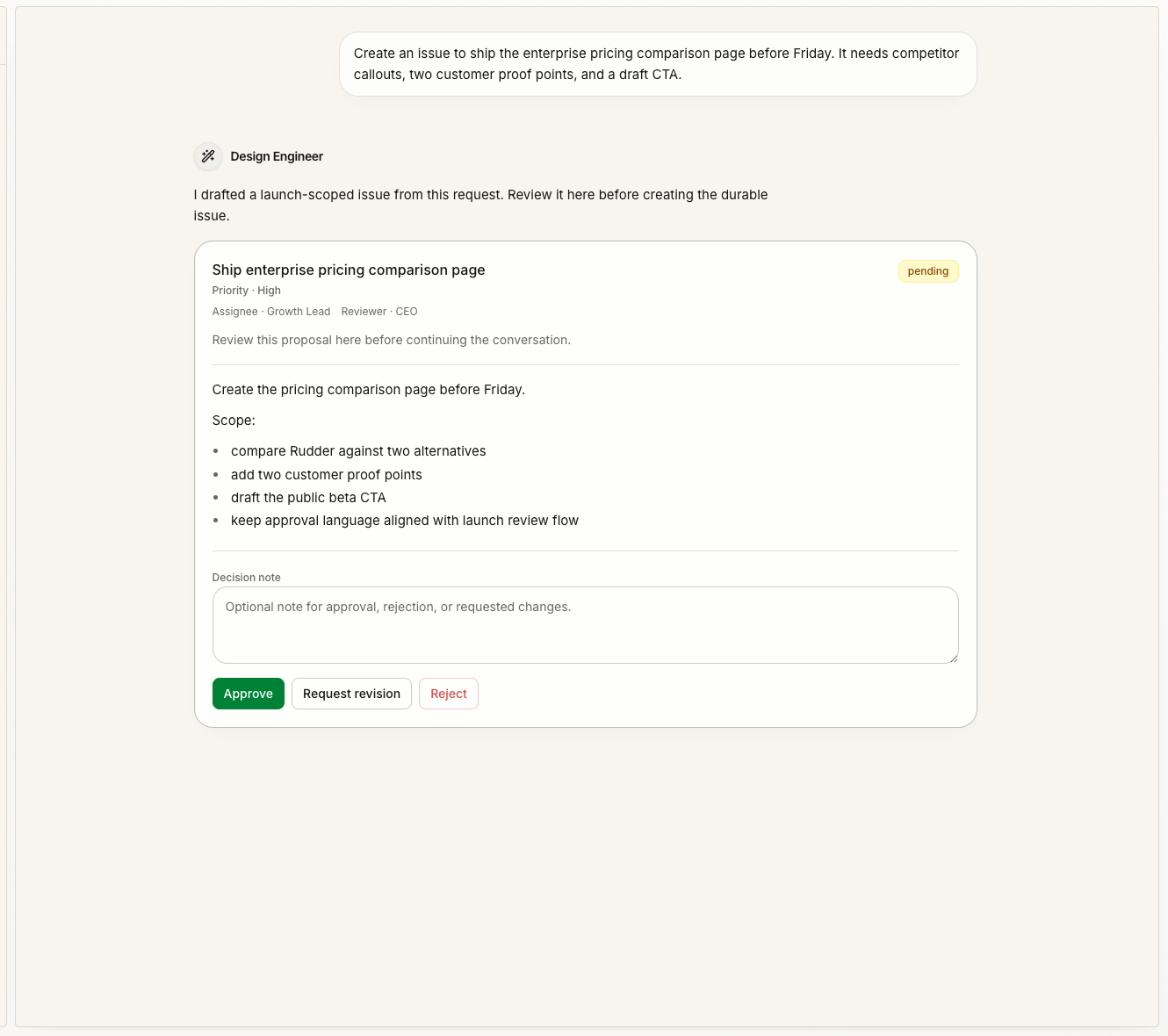 好的模式是:
好的模式是:
- 在 Chat 里输入混乱请求。
- 让选中的 agent 追问或生成 issue 提案。
- 批准或编辑这个提案。
- 执行生成出来的 issue。
- 后续决策继续记录在 issue 上。
8. 用 Messenger 恢复注意力
Messenger 用来发现什么需要人类注意:回复、issue 线程、失败运行、阻塞、决策请求和系统提示。 这些情况应该看 Messenger:
这些情况应该看 Messenger:
- agent 提问
- 失败 run 需要处理
- 阻塞需要人类回答
- review 决定在等待
- Chat 创建的 issue 提案需要接受或编辑
9. 把重复指令沉淀成技能
跑过几条 issue 后,你会看到重复操作:发布检查、预览环境、transcript 调试、文档 review、mock 数据截图等。流程稳定后,把它们沉淀成技能。 一次性说明留在 issue 里。可复用流程放进技能里,未来 agent 就不用每次复制长 prompt。
一次性说明留在 issue 里。可复用流程放进技能里,未来 agent 就不用每次复制长 prompt。
第一条有用循环
当你能追踪下面这条链路时,第一个组织就真的跑起来了:- 人类提出目标。
- 请求变成 issue。
- 一个 assignee 拥有下一步。
- agent run 留下证据。
- reviewer 或 owner 接受、阻塞或要求修改。
- Messenger 显示注意力需求。
- issue 保留最终记录。
下一步
任务生命周期指南
学习什么时候分配执行者、设置 reviewer 和更新 issue 状态。
创建 Agent
需要新角色时,再添加有清楚职责和 runtime 的 agent。
Chat 和 Messenger
理解对话入口和注意力恢复如何配合。